El web scraping también se suele conocer como extracción de datos web, es un método automatizado para extraer grandes cantidades de datos de las páginas web y normalmente estos datos no suelen estar estructurados o ordenados y con estos métodos ya si podemos ordenarlos.
¿Qué es web scraping?
Consiste en realizar una extracción de datos, ejecutamos un código que manda una petición a la URL objetivo y la página web responde a la petición devolviendo datos con los que puede permitir leer su XML o HTML.
Pero al ser automatizado y trabajar a unas velocidades muy altas podemos colapsar sin querer la página web a la que se lo hacemos y puede dar lugar a hacer una acción ilegal contra esa empresa por tirar su página. Además también por extraer información de páginas web, hay que controlar qué podemos extraer y qué no.
Eso lo podemos ver con el robots.txt. El robots.txt es un fichero de texto que podemos encontrar en los sitios web, de hecho si utilizamos cualquier sitio web como facebook.com y le ponemos facebook.com/robots.txt podemos encontrar su archivo robots.
La finalidad de este tipo de archivos es mostrarle a los rastreadores web o crawlers, y a los motores de búsqueda, que partes del sitio web deben ser rastreadas y cuales ignoradas.
Ejemplo de Facebook:
Primero lo ponemos en la URL

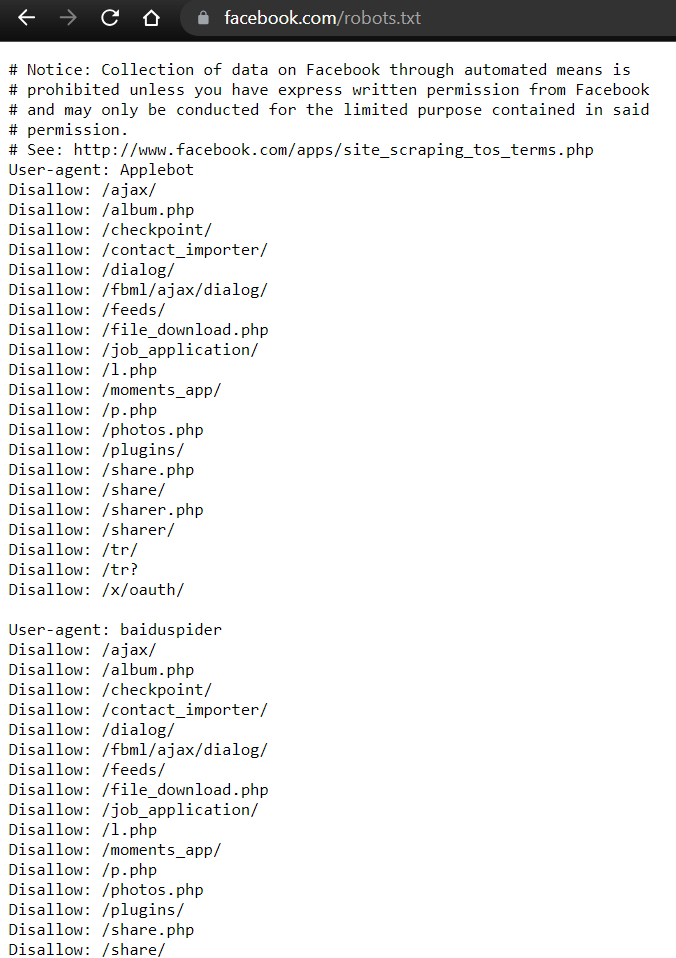
Como vemos, al principio del txt hace un comentario en inglés con las prohibiciones de búsqueda.
Luego si nos fijamos en la sintaxis tenemos el User-agent y el disallow.
El User-agent indica el tipo de bot o agente y debajo de este se indica donde podrá o no acceder.
En caso de acceder es Allow que actúa como lista blanca y no poder acceder es un Disallow que actúa como lista negra y si no pone nada es que se puede acceder libremente.
También mirando robots de diferentes páginas podemos encontrar indicaciones con asteriscos.
Como el caso de esta página web:
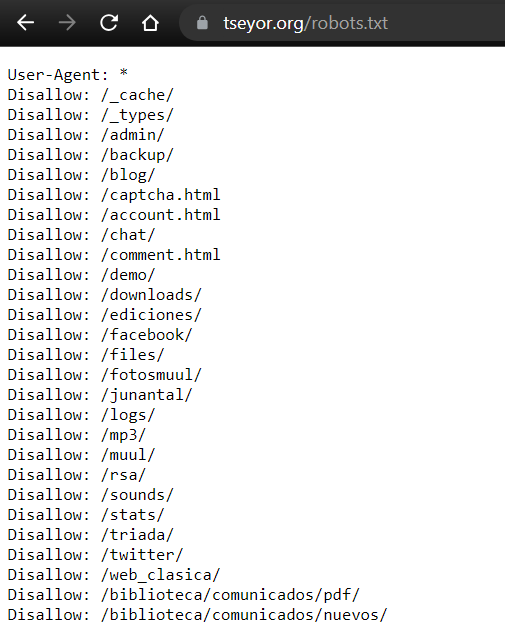
El asterisco indica que cualquier agente tiene prohibidos esos accesos.
Pero realmente el robots.txt solo está haciendo indicaciones, se pueden ignorar estas reglas y eso si puede suponer en acciones ilegales pero hay que recalcar que esta información es pública y aunque sea pública debemos tener cuidado.
Aunque las página web deberían tener medidas de seguridad en caso de que un agente acceda a una fuente de información que no quieren que sea accesible.
¿Cómo hacemos web scraping?
Un lenguaje de programación muy útil para automatizar procesos y hacer bots para este tipo de acciones es Python. Usaremos Python para crear una herramienta básica de web scraping, utilizando diferentes librerías como Selenium y Beautiful Soup.
Selenium es para testeo de páginas web, se utiliza para automatizar actividades de navegación y BeautifulSoup, es para analizar los documentos HTML y XML (esenciales en páginas web) Y crear un estructura en árbol de los datos analizados para poder extraerlos fácilmente para su posterior tratado.
Entonces queremos obtener información de una tienda en internet, principalmente de las laptops y los precios de estas. Vamos a usar de ejemplo a Flipkart, una página india. Para ello primero tenemos que inspeccionar la página para saber decirle al programa que vamos a desarrollar, qué y dónde tiene que buscar.
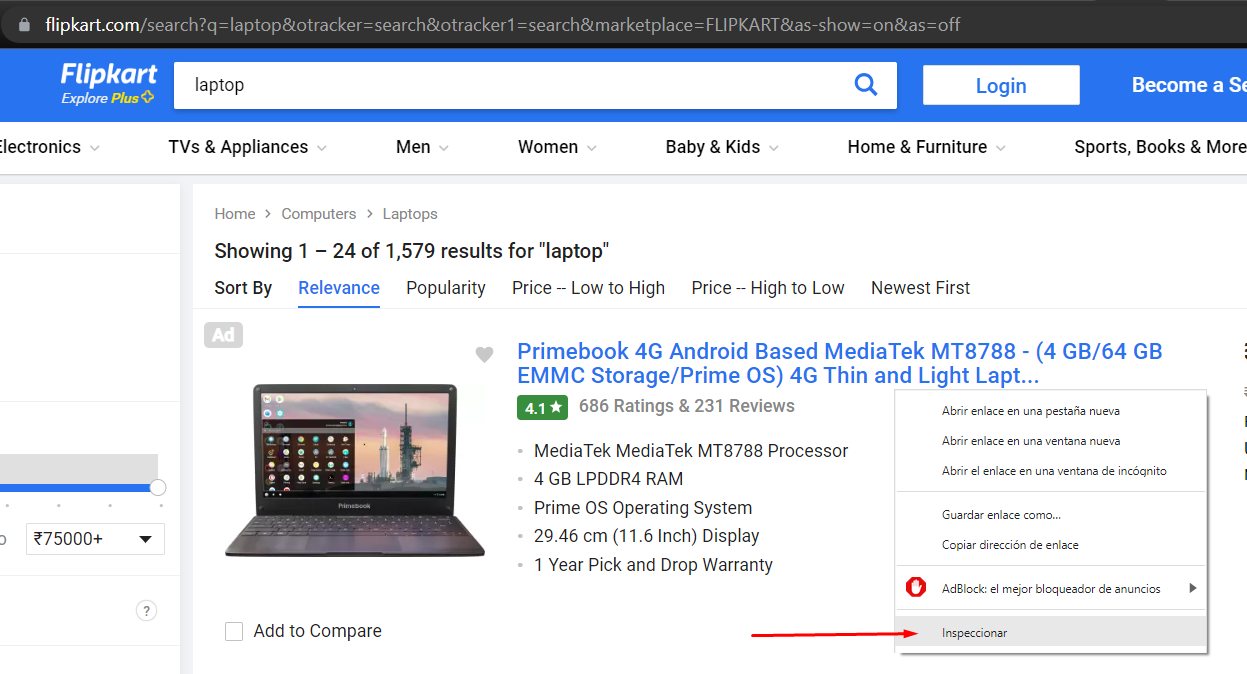
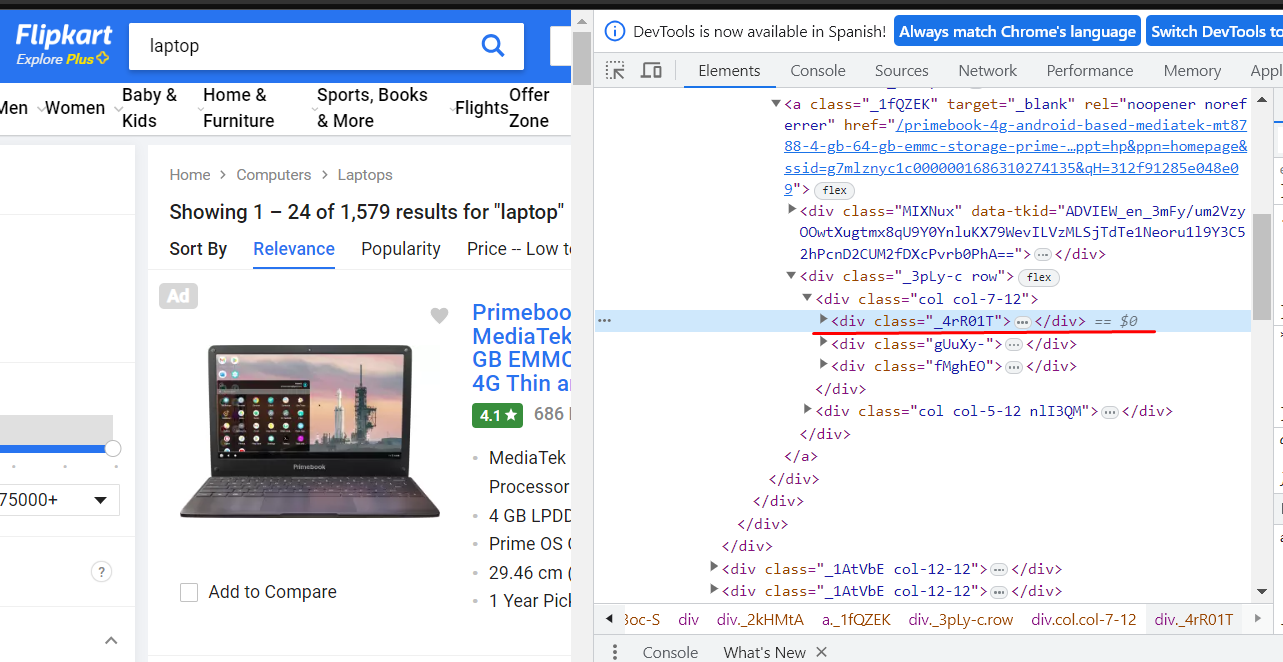
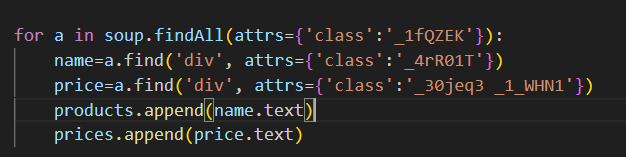
Usamos de referencia los componentes div, en específico los class de estos que es la forma que tenemos para identificar unos divs de otros.
Vemos los contenedores del HTML y al desplegar el div de _4R01T…
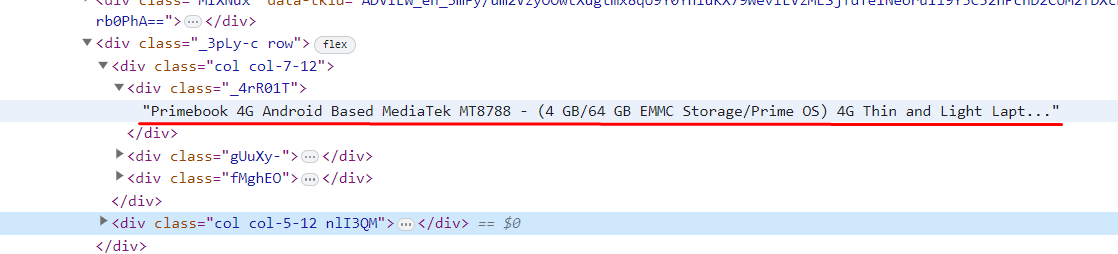
Tenemos ahí el nombre del ordenador, hay que tenerlo en cuenta para nuestro programa
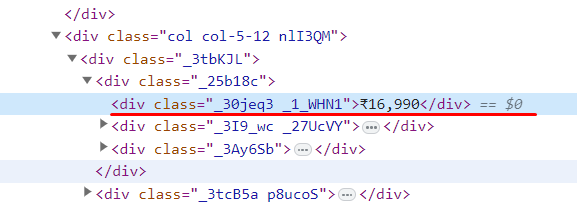
El precio
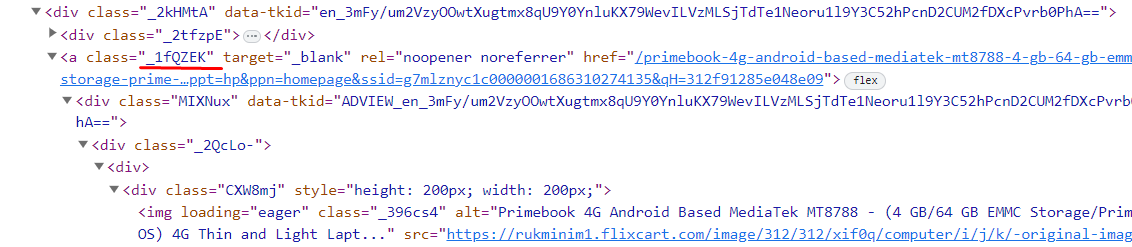
Y la clase con la que hace referencia al nombre
PROGRAMANDO
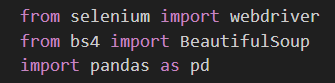
Usaremos Selenium, pandas y BeautifulSoup para esta práctica.
Necesitaremos descargarnos ChromeDriver para que Python pueda hacer las búsquedas necesarias para realizar el web scraping.
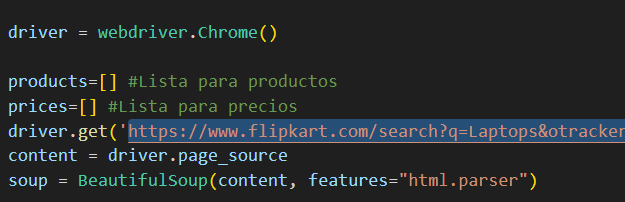
Después realizamos un bucle para recopilar toda la información de esa página según los componentes HTML que hemos encontrado, pasándole los atributos de div y class.
Por último con pandas lo pasamos a csv.

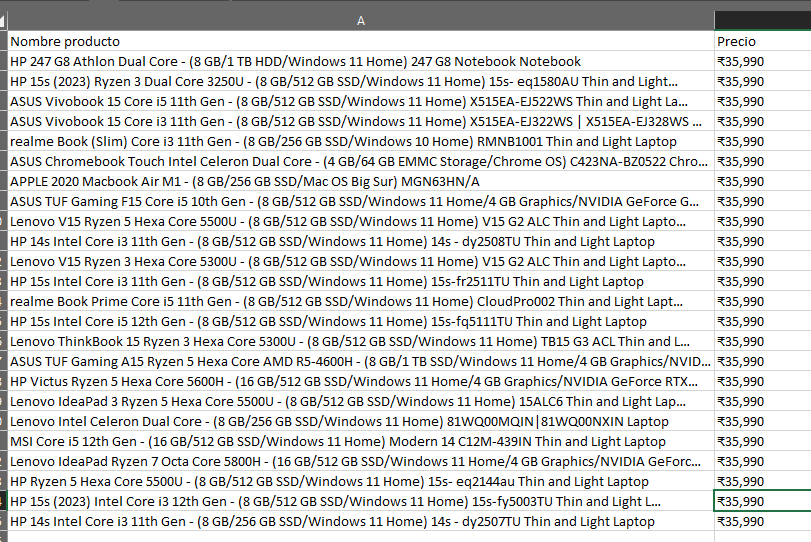
Finalmente estos son los resultados que obtenemos:
Web Scraping en el día a día
Como podemos ver es un caso bastante práctico para visualizar cómo funciona un caso básico de Web Scraping luego con estos datos que conseguimos con el programa podemos hacer estadísticas y sacar estimaciones. Por ejemplo subidas y bajadas de precio de estos dispositivos, en este caso incluso se podría estudiar de India y comparar con precios de otros países de ordenadores y con estas medidas evaluar y monitorizar la competencia y sus productos.
También tiene aplicaciones en el análisis de mercado como para identificar las tendencias y comprender el comportamiento del consumidor.
Luego, podemos crear una herramienta con la que hacemos seguimientos de las noticias, artículos, blogs, que pueden facilitarnos mucho el trabajo, con esto también podemos hacer sondeos y trabajar para diferentes investigaciones que necesiten estos datos que de otra manera serían innaccesibles.
Además, tiene aplicación en ciberseguridad, es muy importante saber qué información es accesible de nosotros y mostrar solo lo necesario. Porque un hacker puede extraer información sensible que no queríamos tener expuesta y es importante ser conscientes de lo que deberíamos tener privado o no.
Por último, si te ha interesado el Web Scraping, te recomiendo que mires este Curso de Web Scraping que ofrecemos en INESEM.



